SN9使用IOTA架构实现大规模AI模型训练
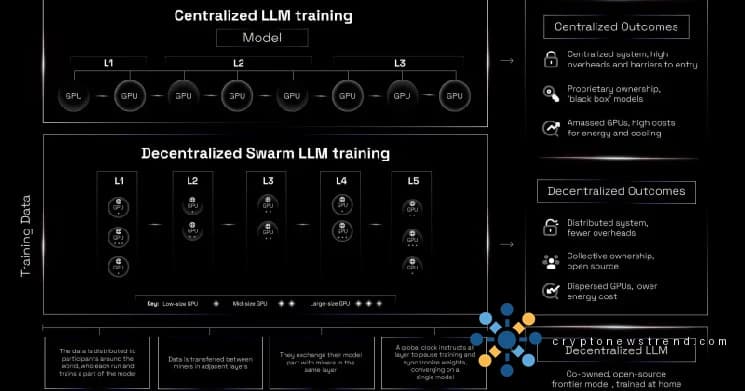
训练大型语言模型通常需要一个装满 GPU 的仓库、七位数的云计算费用,以及只有少数公司拥有的组织力量。 Bittensor 的 Subnet 9 正试图用一种名为 $IOTA 的新架构来翻转这个脚本,$IOTA 是激励协调训练架构的缩写,它将大量 AI 模型分割到多台机器上,因此没有一个参与者需要将整个模型保存在内存中。
从赢家通吃到集体流水线
SN9 的早期版本在竞争模型上运行。矿工们本质上是互相竞争,只有表现最好的人才能获得奖励。到 2024 年 8 月,该设置已成功预训练了包含多达 140 亿个参数的大型语言模型。
但赢者通吃的做法是有上限的。它阻止了无法与资源充足的矿工竞争的较小贡献者,并且它在任何单个机器可以处理的问题上造成了自然瓶颈。 $IOTA 于 2025 年 7 月 16 日在 arXiv 上发布,重新思考了整个激励结构。
广告
矿工现在不再是孤立的竞争对手,而是充当协作管道中的节点。该架构集成了管道并行性和数据并行性,这两种技术借鉴了主要人工智能实验室内部分配训练工作负载的方式。 $IOTA 下的奖励根据所有管道矿工的实际贡献按比例分配给他们,消除了小型 GPU 所有者参与的主要障碍。
在客厅训练人工智能模型
该架构的实际扩展于 2026 年 2 月推出“Train at Home”,这是一款消费者应用程序,可让 Mac 用户将 GPU 算力贡献给训练管道。该应用程序通过一个协调器来处理贡献者之间的协调。它均匀地分配模型层并管理奖励分配,因此个人用户不需要了解底层的管道机制。
这对投资者意味着什么
加密领域的大多数“去中心化计算”项目都专注于推理、运行已经训练好的模型,而不是从头开始训练新模型。训练要困难几个数量级,因为它需要所有参与节点的紧密同步、大量数据吞吐量和一致的正常运行时间。
$IOTA 的管道并行方法通过在机器之间分割模型层而不是要求每个参与者持有完整的副本,避开了内存限制,这些限制历来使分布式训练对于十亿参数模型来说不切实际。 SN9 预训练模型多达 140 亿个参数的先前记录至少提供了一个基线证明,证明该子网可以处理有意义的工作负载。
特别是对于 $TAO 持有者来说,从赢家通吃到按比例奖励的转变可能会有意义地改变子网 9 上的挖矿经济。更广泛的参与意味着对 $TAO 质押的需求更加分散,但这也意味着随着更多矿工加入管道,个人奖励率将会压缩。
训练管道中的恶意或故障节点可能会破坏整个运行的梯度更新。 $IOTA 在实践中如何处理拜占庭容错将决定该架构是否能够从概念验证扩展到生产级培训基础设施。